
PIKAIA - ANSWERS
Answer to Question #1
For any one of the available slot, the probability of getting the letter wrong is 26/27. The probability of getting all 23 letters wrong is then (26/27)^23=0.42Answer to Question #2
For any one of the available slot, the probability of getting the letter right is 1/27. But how does one get from there to the probability of getting at least one letter right in the whole sentence ? Here's an important trick: the probability of an event happening is often easier to compute as one minus the probability of that event not happening. For not getting any letter right, all letters must be wrong. From question #1 we know that the probability of this happening is 0.42. Consequently the probability of getting at least one letter right is 1-0.42=0.58.Answer to Question #3
To get one and only one letter right, we must get one letter right and all other 22 letters wrong. So, the probability is (1/27) times (26/27)^22 times 23 (that last one because there are 23 possible ways to get one right and the rest wrong). So the sought after probability is 0.37.Answer to Question #4
Now this one is trickier a bit. remember the trick given in the answer to question 2; we are better off calculating the probability that all letters remain wrong in all 10 sentences, and then one minus that result is the probability we're after. For this we first need to calculate the probability that one particular letter mutates to the correct one; that's easy (1/27) times the mutation probability (Pm=0.01) = 0.00037. This implies that probability of the letter remaining incorrect is 1-0.00037=0.99963. Now the probability of all letters in all ten sentences remaining incorrect is 0.99963^230=0.91833. So finally, the probability of one letter mutating to the correct one in one of the 10 sentences is 1-0.91833=0.08167; a little under one in ten, not so bad !Answer to Question #5
The probability of this happening is the probability of one specific letter mutating to the correct one (this we calculated on the way to the answer to question #4 as equal to 0.00037) times the probability of all other letters not mutating at all, which is (1-0.01)^22, so that the final sought after probability is 0.00030. Pretty small, isn't it ? Yet about 300 iterations, on average, will suffice. It wouldn't help to increase the mutation probability, because even though this would increase the probability of mutating to the correct letter (proportional to Pm), it would decrease the probability of not mutating the other letters (proportional to a high power of 1-Pm). You may have guessed that there is an ``optimal'' value of Pm that will minimize the number of iterations required to make that last step from 22 right/1 wrong to the target sentence. That value, however, is dependent on the sentence length, alphabet size, and the stage at which the evolution has arrived (i.e., how many right/wrong letters). The following diagram illustrates three evolutionary runs with Pm=0.1, 0.01 and 0.001 respectively: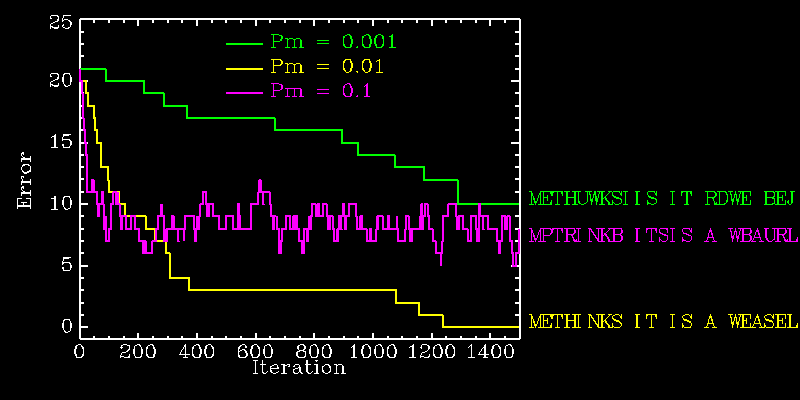
 Click here to view full size diagram
Click here to view full size diagram
Note how the rate of error decrease, early in the evolutionary run, is proportional to the mutation probability Pm. Later on, however, the high Pm run levels off at a more or less constant error value. This represents a form of equilibrium between mutation producing new correct letters, while simultaneously wiping our previously correct letters. Mutation is a double-edged tool...
Answer to Question #5
This objection is valid, but not overwhelmingly so. All that is needed for selection to proceed is to establish a relative ranking among the various trial solutions (i.e., which solution is doing better/worst than a given other solution, or the average). In our WEASEL example this ranking is indeed established through an absolute measure of closeness of fit to a known target sentence, but this is not essential.Answers to Breeding Subpage
Answer to Question #1
Were it not for the crossover component of the breeding process, this would be essentially identical to the procedure used in the WEASEL example. Crossover, in fact, is the genetic consequence of sex. Strictly speaking, the form of crossover implemented in most genetic algorithms differs from the ``standard'' crossover in diploid genetic systems, where crossover refers to the exchange of genes between two homologous chromosomes during meiosis.Answer to Question #2
According to the discussion in section 4 of the breeding subPage, one should expect that m(s,t+1)=m(s,t) times f(s)/F, so that we should have
m(s,t+1)=m(s,t)(1+c)
which, if c remains constant,
has a general discrete solution in the form
m(s,t)=m(s,t=0)(1+c)^t
which describes geometric growth.
Answer to Question #3
(a) The probability of crossover not disrupting a schema is the probability of the splicing point not falling between the leftmost and rightmost components of the schema. First calculate the probability of the splicing point to indeed fall within the length of the schema; with a full chromosome length of Ly and schema defining length of D, that probability is (D-1)/L times the crossover probability Pc. The probability of not being disrupted by crossover is then 1-Pc(D-1)/L.(b) The needed probability is just the probability of any of the defining site not being hit by a mutation; for a single site that probability is 1-Pm; for N sites the net probability is (1-Pm)^N.
(c) This is simply the product of the two probabilities calculated in (a) and (b)
(d) The two expressions can be brought in agreement under the assumption that (1) the schema defining length is much smaller than the full chromosomal length (i.e., (D-1)/L is much smaller than one), and (2) the mutation rate is much smaller than one, in which case (1-Pm)^N is approximately equal to 1-N Pm; if both those conditions are satisfied, then the cross product term (Pc(D-1)/L times N Pm) resulting from the product of the probabilities calculated in (a) and (b) is also much smaller than the other terms, and consequently can also be neglected, so that one finally arrives at the quantity within square parentheses in the expression given under the breeding Homepage.