High Altitude Observatory
The power of Natural Selection
This Page presents a little example demonstrating the power of cumulative selection based on fitness. The example is borrowed from the textbook Evolutionary Genetics by John Maynard Smith, who himself borrowed it from Richard Dawkin's book The Blind Watchmaker.
Consider the following sentence (one of the lesser-known lines of Hamlet, apparently):
METHINKS IT IS A WEASEL
This sentence is made up of 23 symbols, extracted from a 27-letters alphabet (counting a blank as a letter). This is the target sentence. Now for each of the 23 available slots, select a letter randomly from the 27-letters alphabet; the probability of a given slot being filled with the correct letter is obviously 1/27. The probability of all 27 slots to be filled with the correct letter is 1/27 multiplied with itself 23 times. With the letters selected randomly, expressed as a fraction the chances of reproducing the target sentence on the first try are
1 / 83438516833108049000000000000000
which would look far less idiotic if this #%#%#% html knew about exponents (note that this is computed only to 16 digits accuracy, so that the trailing series of 15 zeros are not significant digits). That denominator is a large number, obviously, but how large really ? A lot larger than you probably think. If the Earth's surface were to be covered with sand made of grains of 10 microns diameter (high quality beach stuff), this sand layer would have to be 6.4 kilometers thick to contain that many grains of that very fine sand. Randomly producing the correct target sentence would be equivalent to sticking your hand into that mother of all sandboxes, hoping to pick out the one single grain of sand with your name carved on it. Good Luck.
Consider now instead the following procedure:
- Generate 10 sentences of 23 randomly chosen letters.
- Evaluate the fitness (defined here as the number of correct letters) for each of the 10 sentences.
- Pick the best sentence (or, if more than one has the same, highest fitness, pick one of those randomly), an duplicate it ten times.
- For each one letter of each of the 10 duplicates, do the following: generate a number R between 0 and 1. If R is smaller than a preset mutation probability Pm=0.01, replace that letter by a new letter selected randomly from the 27-letters alphabet. This represents a mutation !
- Repeat steps 2 through 4 until the target sentence is produced.
How many iteration cycles will be needed to produce the target
sentence ? Most likely less than with the purely random process
described previously, right, but how much less ? Make a guess and then
start the following animation to see the answer.
This animation displays the best of each successive ten iteration.
The yellow number to the
left is the iteration count,
and the number of incorrect letters is indicated in green to the right.
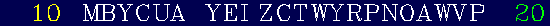
Click on the above to view animation [Size: 300 KB]
1240 iterations. That's many, many, many times less than through purely random trial and error (even taking into account the fact that each iteration involves producing ten trial sentences). The solution procedure does incorporate a stochastic component, so that evolution starting from different sets of 10 random sentences will end up requiring different numbers of iteration cycle to reach the target sentence. It can actually be shown that the most probable number of iteration required is of order of a few thousands, so that the 1240 iterations required on the animation do represent a typical result.
Note that this procedure has three defining characteristics. The first one, of course, is natural selection: it is the best, and only the best, of each 10-sentences generation that is chosen to produce the next generation. The second feature is inheritance: offspring look a lot like their progenitor. (because the mutation probability is much smaller than one). The third is variation; new letters are continuously introduced into the population, via the occurrence of mutations. All three of these features are essential aspects of the biological evolutionary process, and all three are built into genetic algorithms. The only missing component, in this example, is sex. If sexual reproduction is so ubiquitous among living organisms, one should suspect that it may be advantageous in some way, a topic to be explored on a different Page.
Questions and Answers:
- What is the probability of getting not a single correct letter on the initial random sentence generation ? [answer]
- What is the probability of getting at least one correct letter on the initial random sentence generation ? [answer]
- What is the probability of getting one and only one correct letter on the initial random sentence generation ? [answer]
- In a given pass of the mutation operator on the set of 10 23-letter sentences, what is the probability that at least one letter in one of the sentences mutates to the correct letter, if originally none of the letters in any of the sentences were correct ? [answer]
- OK, your sentence has now evolved to the point where your best has 22 correct letters, and only one to go. What is the probability of finally getting the full correct sentence in one pass of the mutation operation on your best sentence ? Would it help to increase the mutation probability ? [answer]
- One may argue that this whole WEASEL business is actually a misleading example of the power of natural selection; fitness is calculated with respect to an absolute standard of ``perfection'', moreover known a priori. Nothing like that in the biological world (n'en deplaise a Teilhard de Chardin). Is this really a serious objection ? Why ? [answer]